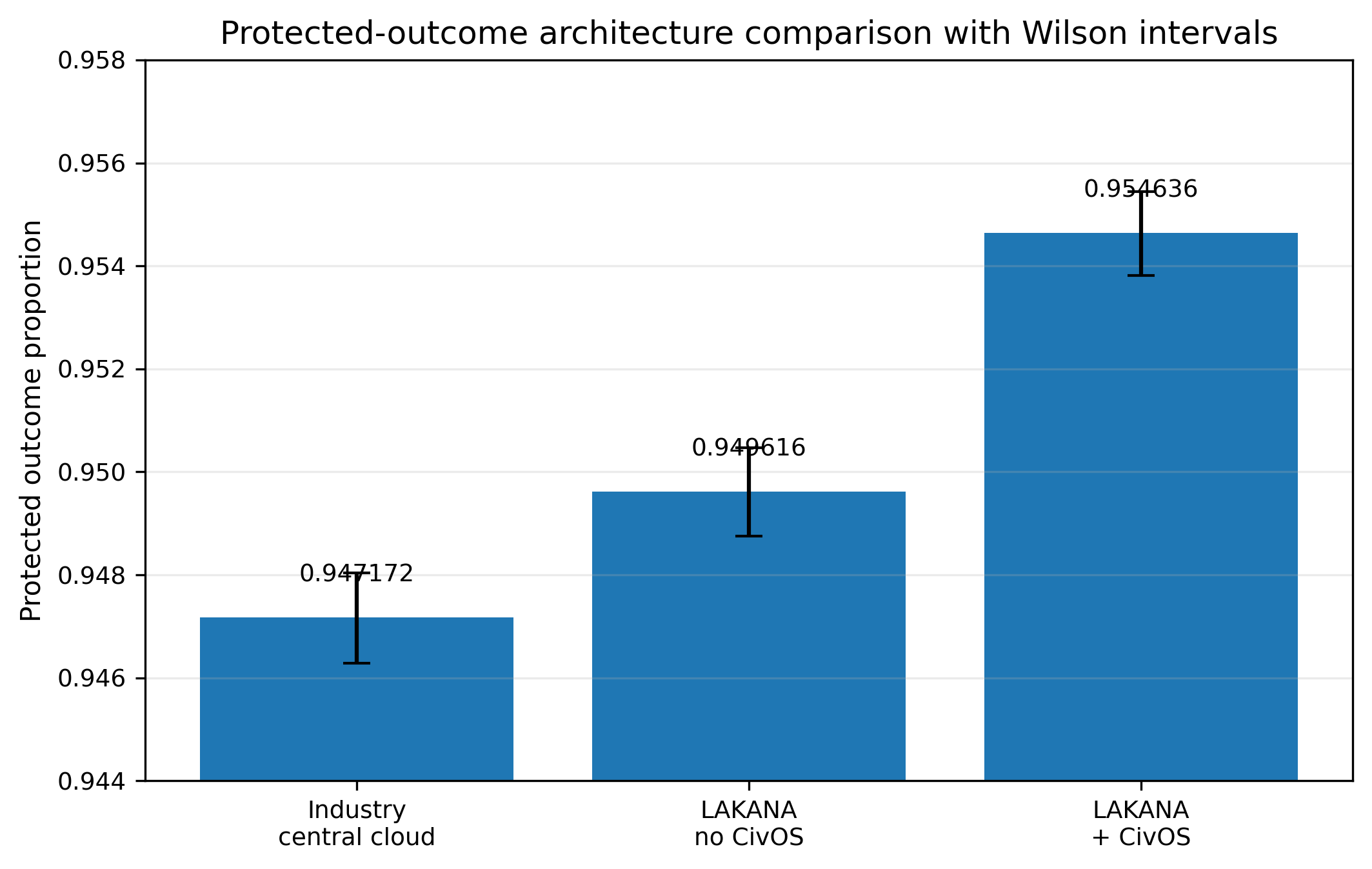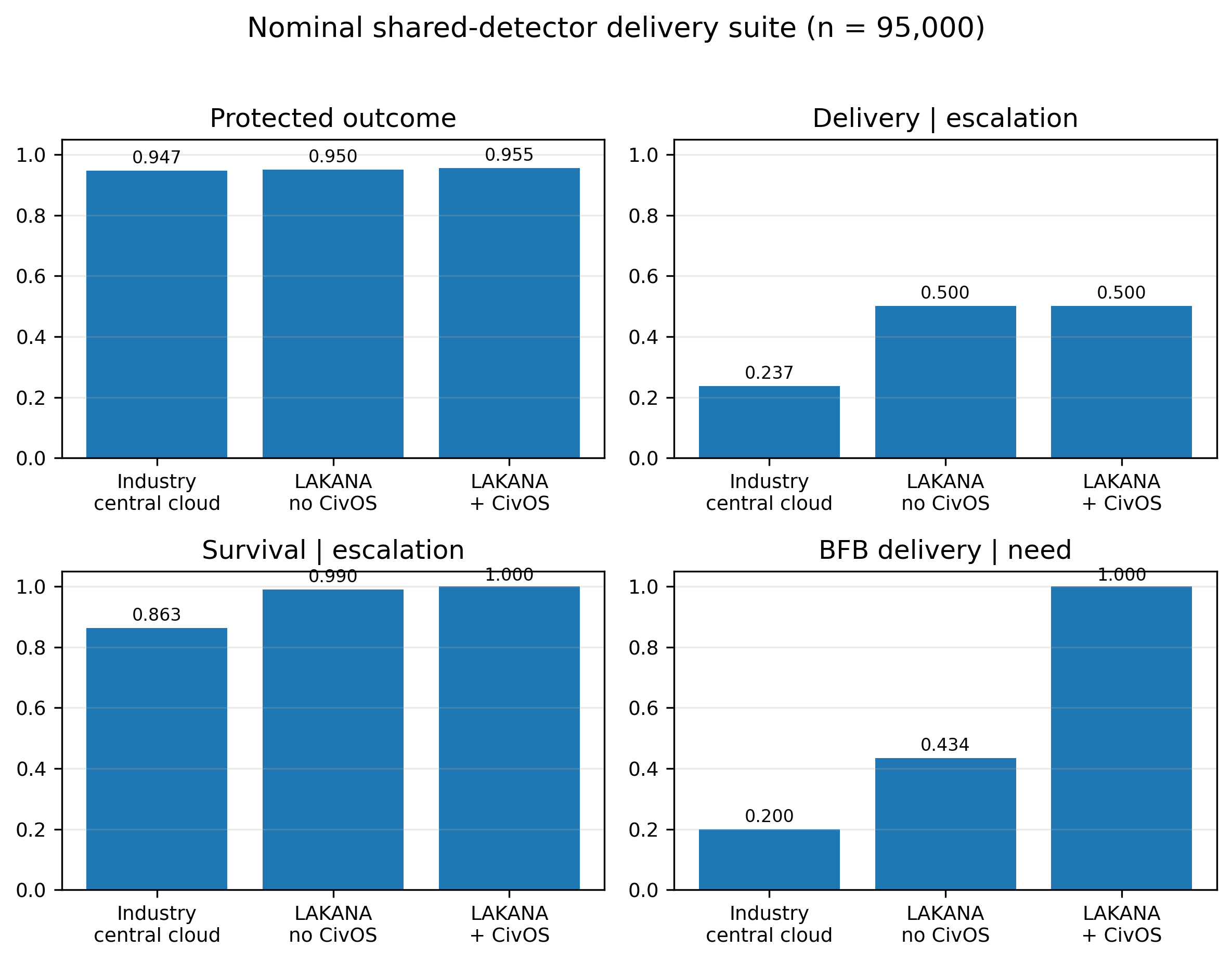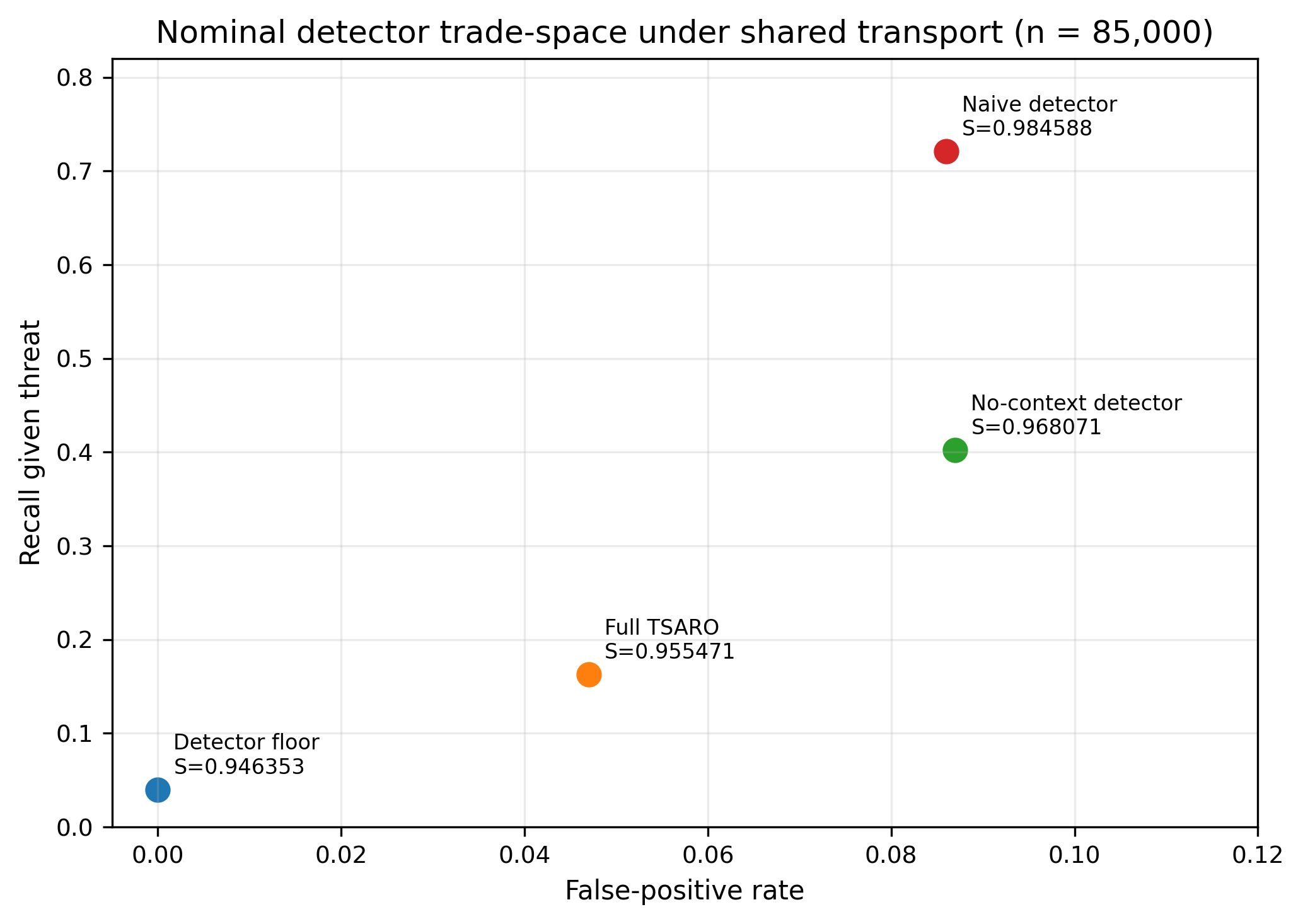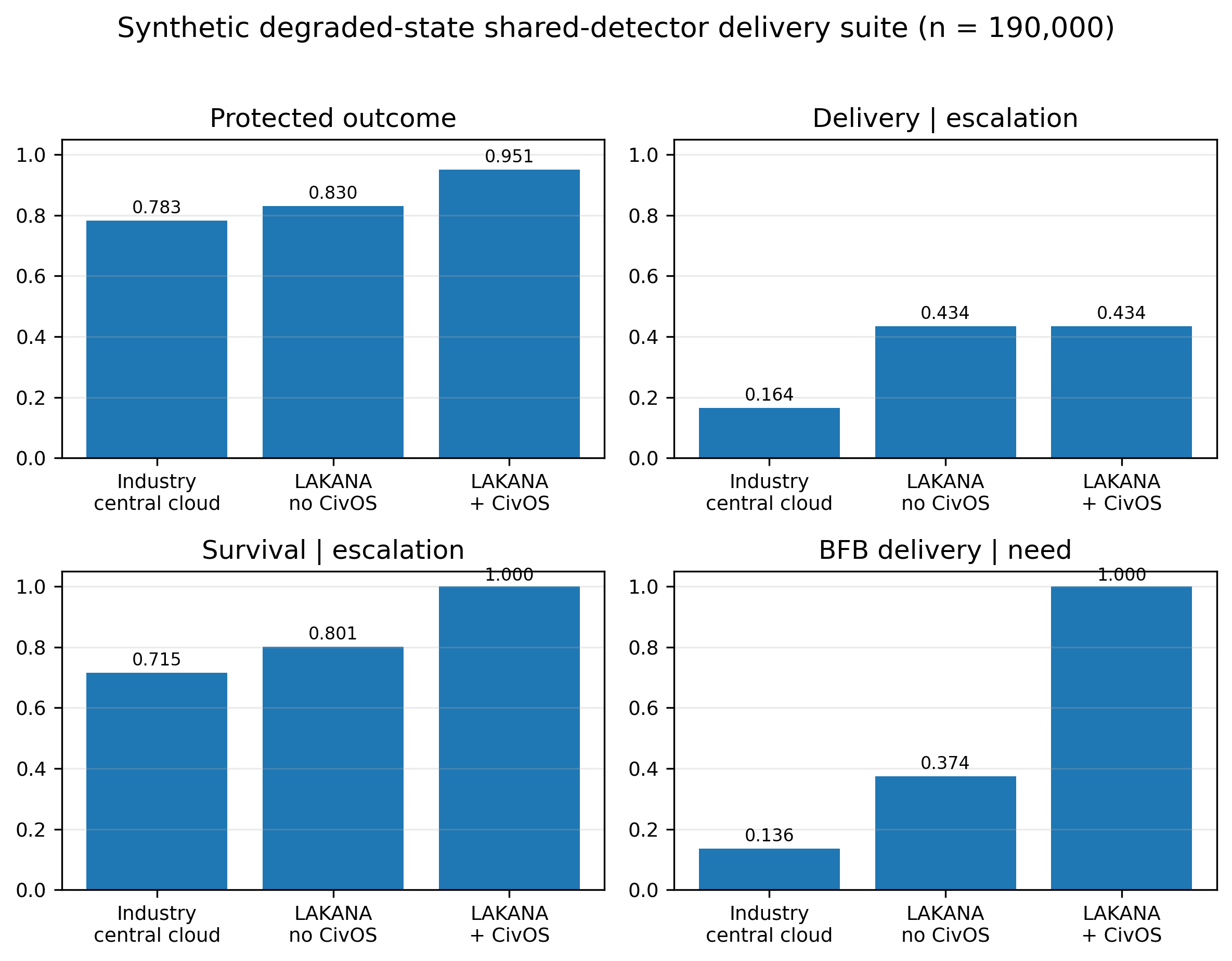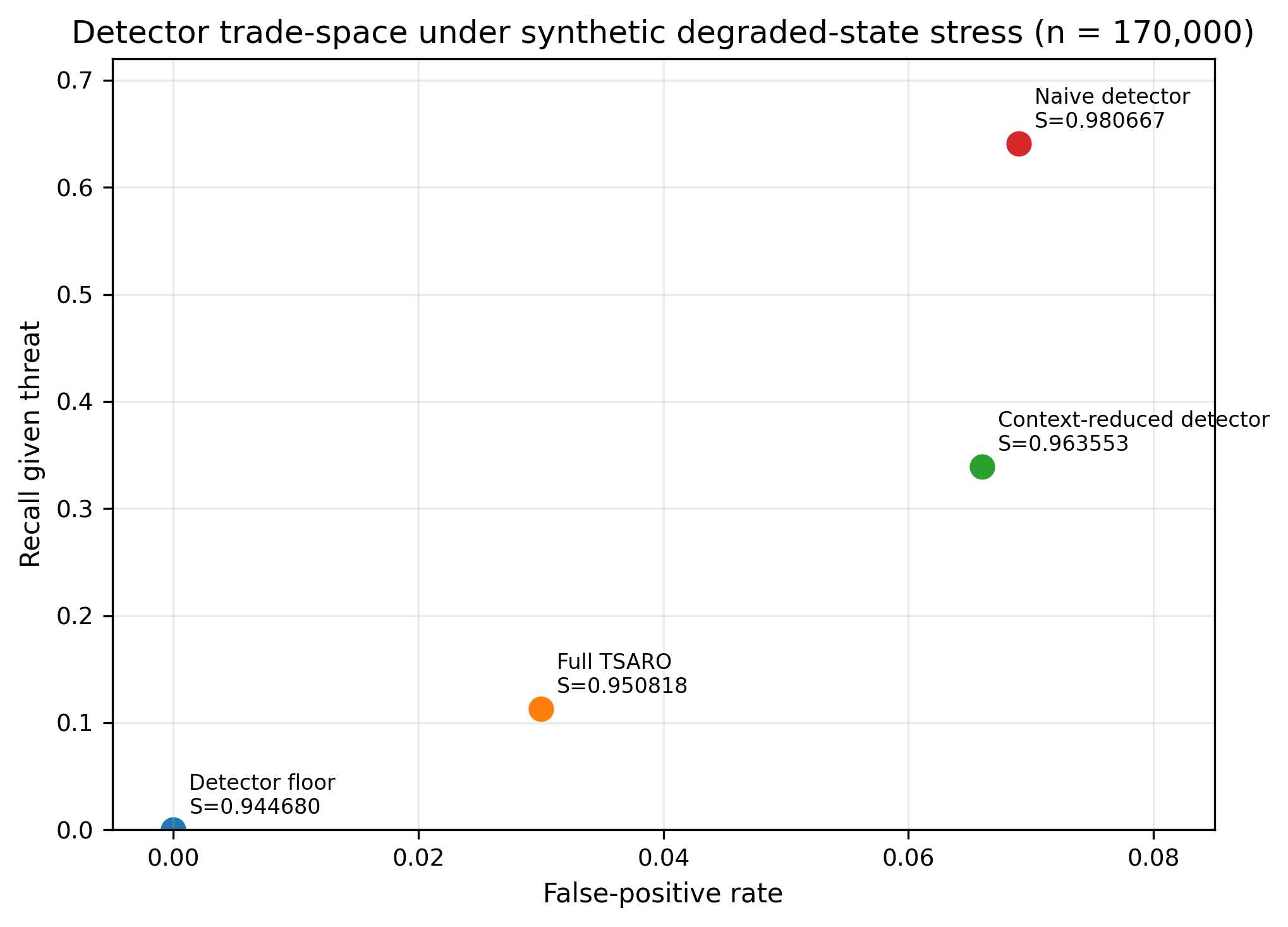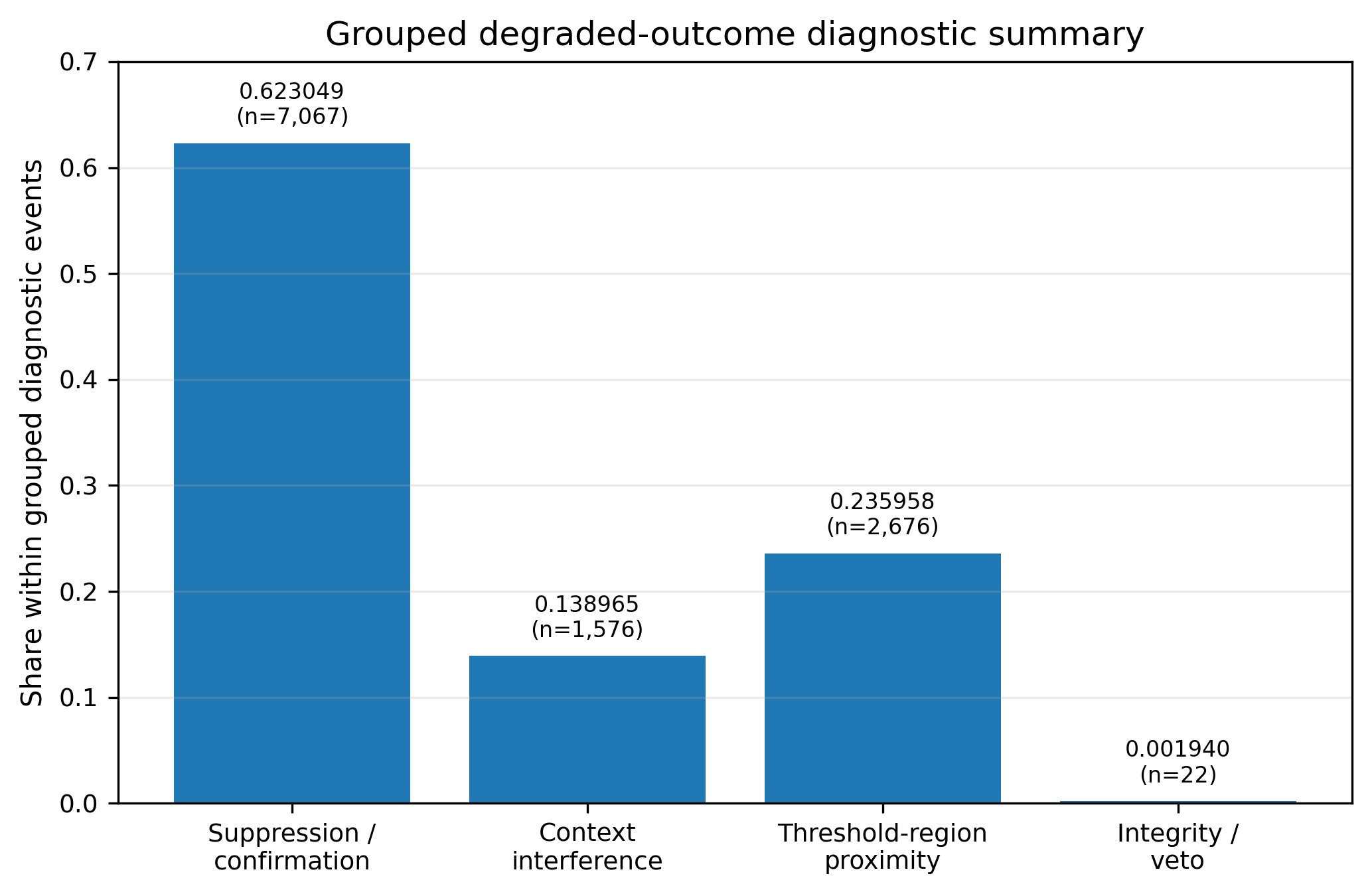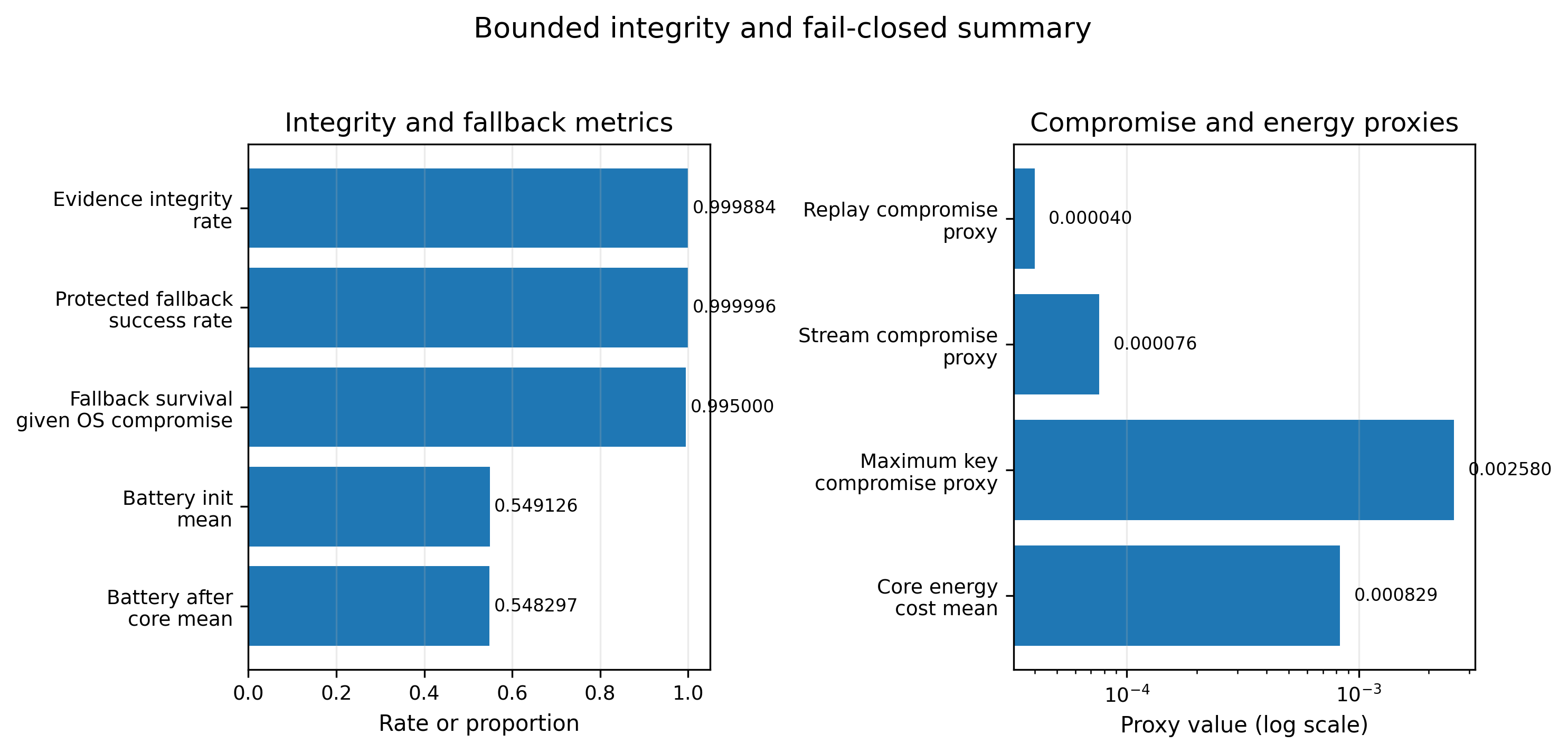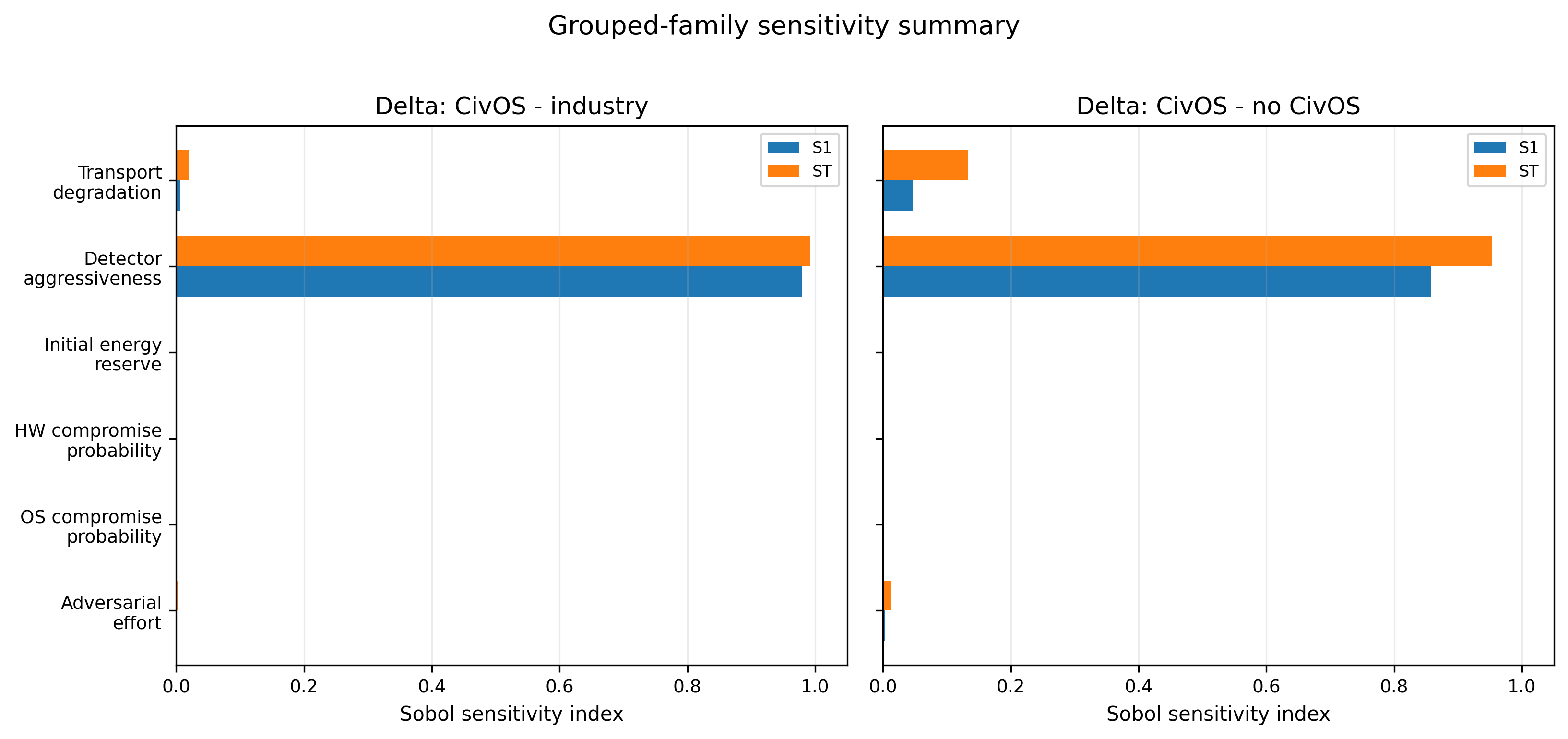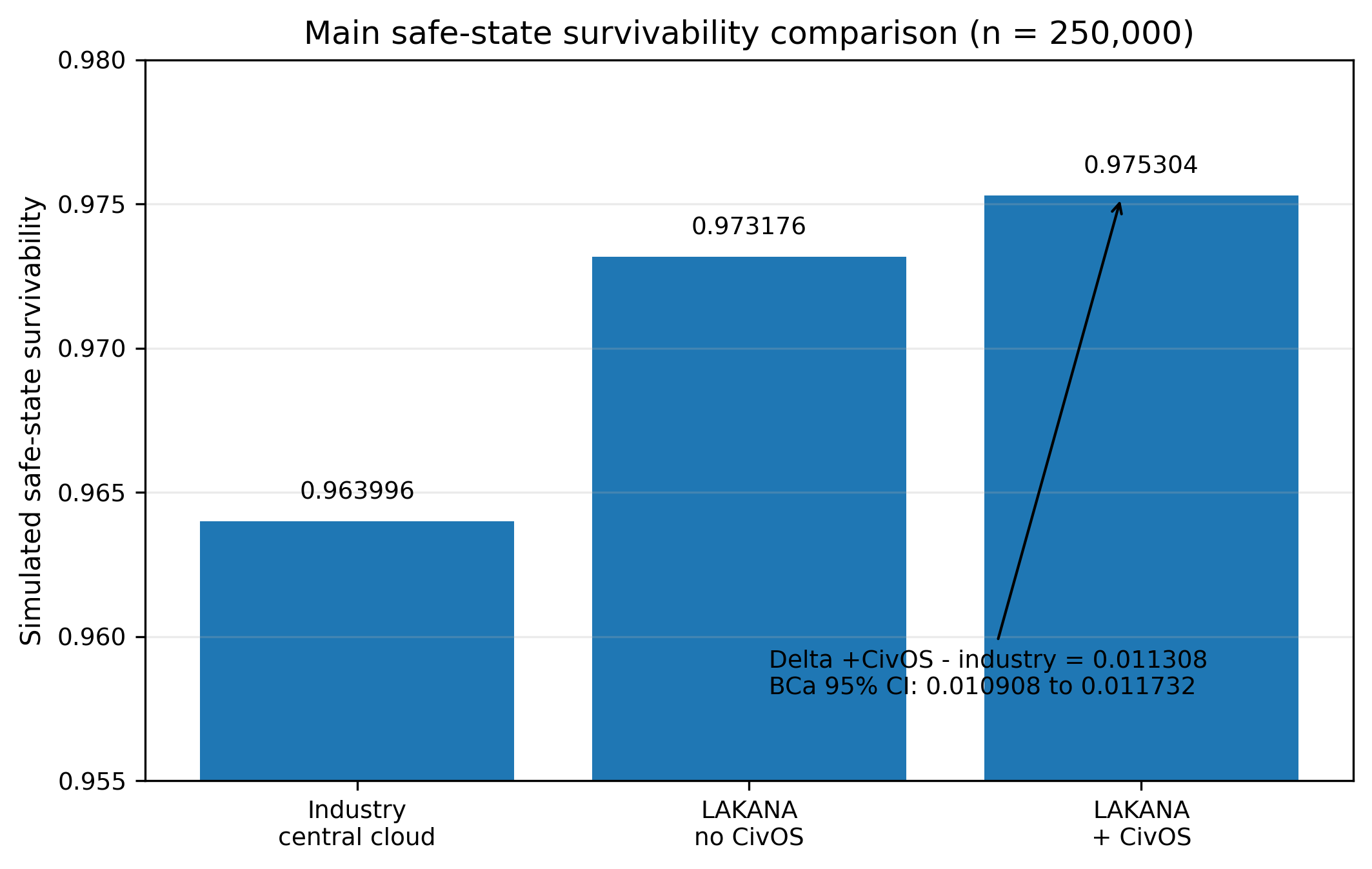
Figure 1 — Safe-State Survivability
Main safe-state survivability comparison (n = 250,000). The simulation-internal survivability metric reports 0.963996 for the industry-style centralized/cloud comparator, 0.973176 for LAKANA without CivOS, and 0.975304 for LAKANA+CivOS. The LAKANA+CivOS minus industry delta is 0.011308 with a bootstrap BCa 95% confidence interval of approximately 0.010908 to 0.011732.